本地部署AI
本地运行大语言模型适合三类场景:开发调试需要可控的离线环境、数据合规要求不能上云、希望把模型跑在自有硬件上。不同方案在易用性、性能、可控性、硬件适配上各有侧重。
选型速查
| 方案 | 类型 | 适用 | 学习成本 |
|---|---|---|---|
| Ollama | CLI 工具 + REST API | 快速试用、本地 API 接入、跨平台 | 低 |
| LM Studio | 桌面 GUI | 不喜欢终端、需要图形界面选模型 | 极低 |
| llama.cpp | C++ 推理核心 | 想深入底层、极致性能优化 | 中高 |
| vLLM | Python 推理服务 | 生产级部署、高并发服务 | 中高 |
| MLX / mlx-lm | Apple 官方框架 | M1/M2/M3/M4 芯片极致性能 | 中 |
| llamafile | 单可执行文件 | 跨平台分发、便携场景 | 低 |
选型核心问题:你需要的是一个能跑起来的工具,还是一个能控制细节的引擎。Ollama/LM Studio/llamafile 偏前者,llama.cpp/vLLM/MLX 偏后者。
Ollama
Ollama 是 macOS 上最省心的本地 LLM 运行环境,安装只需要下载 DMG、拖入 Applications、启动即可。
Download Ollama · 模型搜索 · LLM Leaderboard
模型选型
| 模型 | 适用场景 | 备注 |
|---|---|---|
qwen3:8b | 日常对话、代码辅助、轻量分析 | 8GB 显存即可,反应迅速 |
llama3.2-vision | 多模态问答、图像理解 | 11B 起步,桌面 GPU 可用 |
qwen2.5:72b / llama3.2-vision:90b | 高质量分析、研究辅助 | 需要 48GB+ 显存,桌面独占 |
设备与速度参考
| 设备 | 适用模型量级 | 体感 |
|---|---|---|
| MacBook Pro M1 Max 64GB | 3B-11B 可日常共存,70B+ 需独占 | 中小模型与系统操作可并行 |
| Mac Studio M3 Ultra 512GB | 可跑 200B+ 级别 | 大模型体感接近云端 API,延迟仍偏高 |
在 64GB M1 Max 上:3B / 11B 可与系统其他操作共存;70B 级别会让 CPU/GPU 满载数秒,体感接近 ChatGPT-4 但响应明显更慢。
常用命令
# 拉取并运行模型
ollama run qwen3:8b
# 查看本地模型
ollama list
# 查看运行中模型
ollama ps
# 临时切换模型目录
launchctl setenv OLLAMA_MODELS /path/to/new/models
# 永久切换模型目录
ln -s /path/to/new /path/to/models/
LM Studio
LM Studio 是桌面 GUI 客户端,模型列表、HuggingFace 搜索、对话、参数调节、模型量化全部在界面里完成,不需要碰命令行。底层使用 llama.cpp 推理引擎。
适合不想用终端、又希望尝试多个模型快速对比的人。提供 OpenAI 兼容的本地 API,可以直接接入 Claude Code、Cursor 等工具作为本地后端。
llama.cpp
llama.cpp 是整个本地 LLM 生态的推理核心,Ollama、LM Studio、llamafile 的底层都基于它。直接使用 llama.cpp 需要从源码编译或下载预编译版本:
# macOS (Homebrew)
brew install llama.cpp
# 直接下载预编译二进制
# https://github.com/ggerganov/llama.cpp/releases
# 典型推理命令
llama-cli -m model.gguf -p "你好"
直接用 llama.cpp 适合:想控制每一个推理参数(batch size、KV cache 量化、GPU offload 层数)、需要在嵌入式设备上运行、或者要做模型量化实验。代价是要读文档、写编译参数。
vLLM
vLLM 是 Python 推理服务,目标是"让本地 LLM 像云端 API 一样被并发调用"。PagedAttention 等技术让显存利用率远高于 llama.cpp,适合多用户、多请求的生产场景。
pip install vllm
vllm serve Qwen/Qwen2.5-7B-Instruct
# 服务监听在 http://localhost:8000,OpenAI 兼容 API
适合:自己部署一个 OpenAI 替代服务给团队用、Agent 后端需要高吞吐。代价是必须配 Python 环境、对小规模个人使用偏重。
MLX
MLX 是 Apple 官方的机器学习框架,专门为 Apple Silicon 设计,统一内存架构下性能可以显著超过 llama.cpp。mlx-lm 是其上的语言模型加载/推理库:
pip install mlx-lm
# 命令行推理
mlx_lm.generate --model mlx-community/Qwen2.5-7B-Instruct --prompt "你好"
# 启动 API 服务
mlx_lm.server --model mlx-community/Qwen2.5-7B-Instruct
MLX 在 M1/M2/M3/M4 上的优势最明显,且能跑 Hugging Face 上 mlx-community/ 的现成量化模型。如果你的主力设备是 Apple Silicon 且追求最高性能,MLX 值得专门花时间了解。
llamafile
llamafile 是 Mozilla 出的"单文件 LLM 推理"——把模型权重、推理引擎、Web UI 全部打包进一个可执行文件,双击运行就能在浏览器里对话。
适合:跨平台分发模型给非技术朋友、便携 USB 设备、临时演示场景。缺点是模型文件很大(包含权重),且性能调优不如 llama.cpp 灵活。
Open WebUI
无论用上面哪种方案做后端(Ollama、vLLM、llama.cpp server、MLX),都可以用 Open WebUI 作为统一的图形界面。
docker run -d -p 127.0.0.1:3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui --restart always \
ghcr.io/open-webui/open-webui:main
启动后访问 http://127.0.0.1:3000,在设置里把 API 端点指向你的推理后端即可。
公网访问
需要从外网访问本地 Open WebUI 时,最简方案是域名 + Let's Encrypt + Nginx 反代:
# 申请证书(DNS 验证)
sudo certbot certonly --manual --preferred-challenges dns
# 安装并配置 Nginx
brew install nginx
# 编辑 /opt/homebrew/etc/nginx/nginx.conf,配置 SSL + 反代到 127.0.0.1:3000
sudo brew services restart nginx
最小可用的 Nginx server 段:
server {
listen 3000 ssl;
server_name your.domain.com;
ssl_certificate /etc/letsencrypt/live/your.domain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/your.domain.com/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
location / {
proxy_pass http://127.0.0.1:8080;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
}
}
手动申请的证书不会自动续期,到期前重复执行同一条 certbot 命令。
几张图
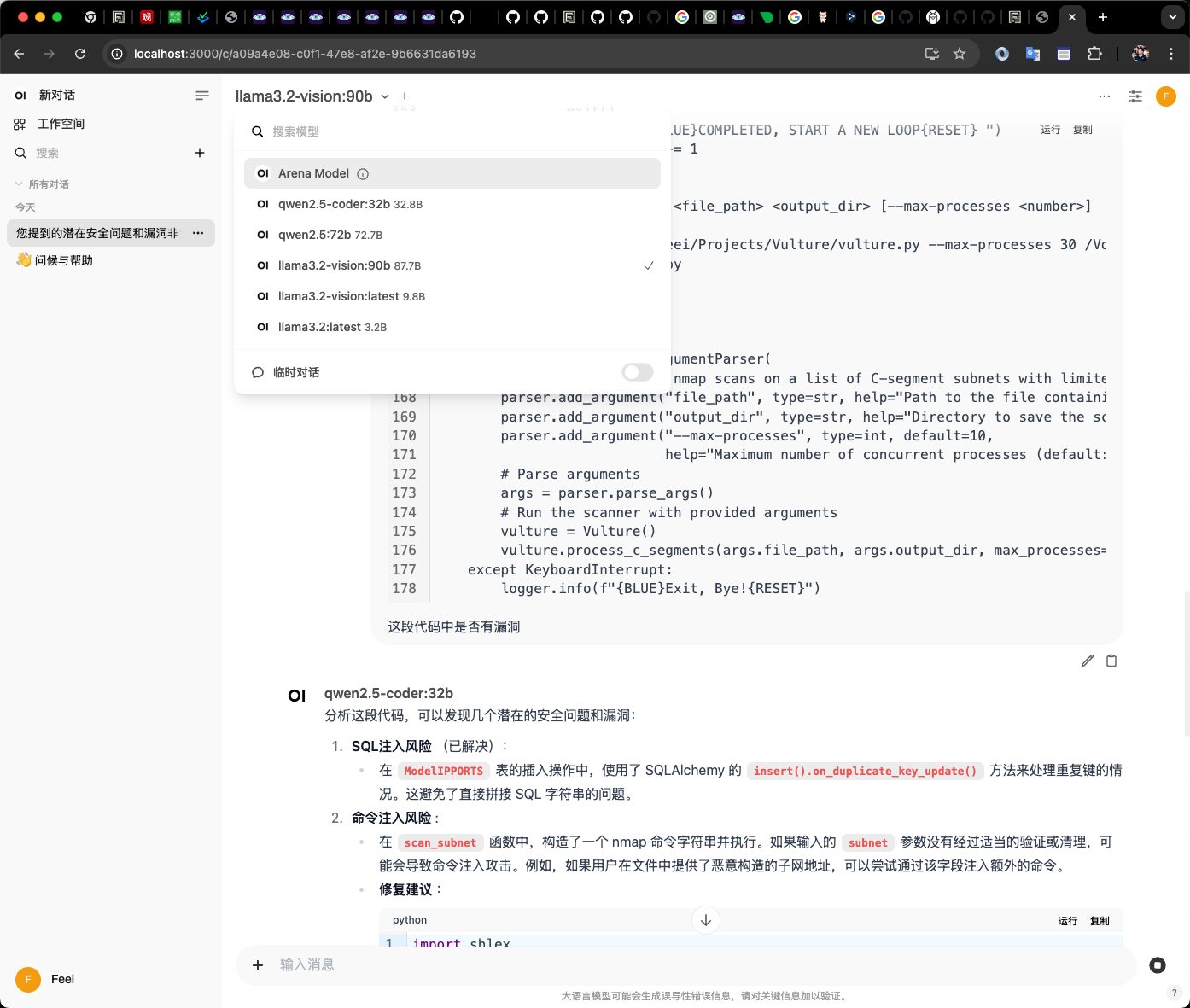
Ollma + Open WebUI 实际界面
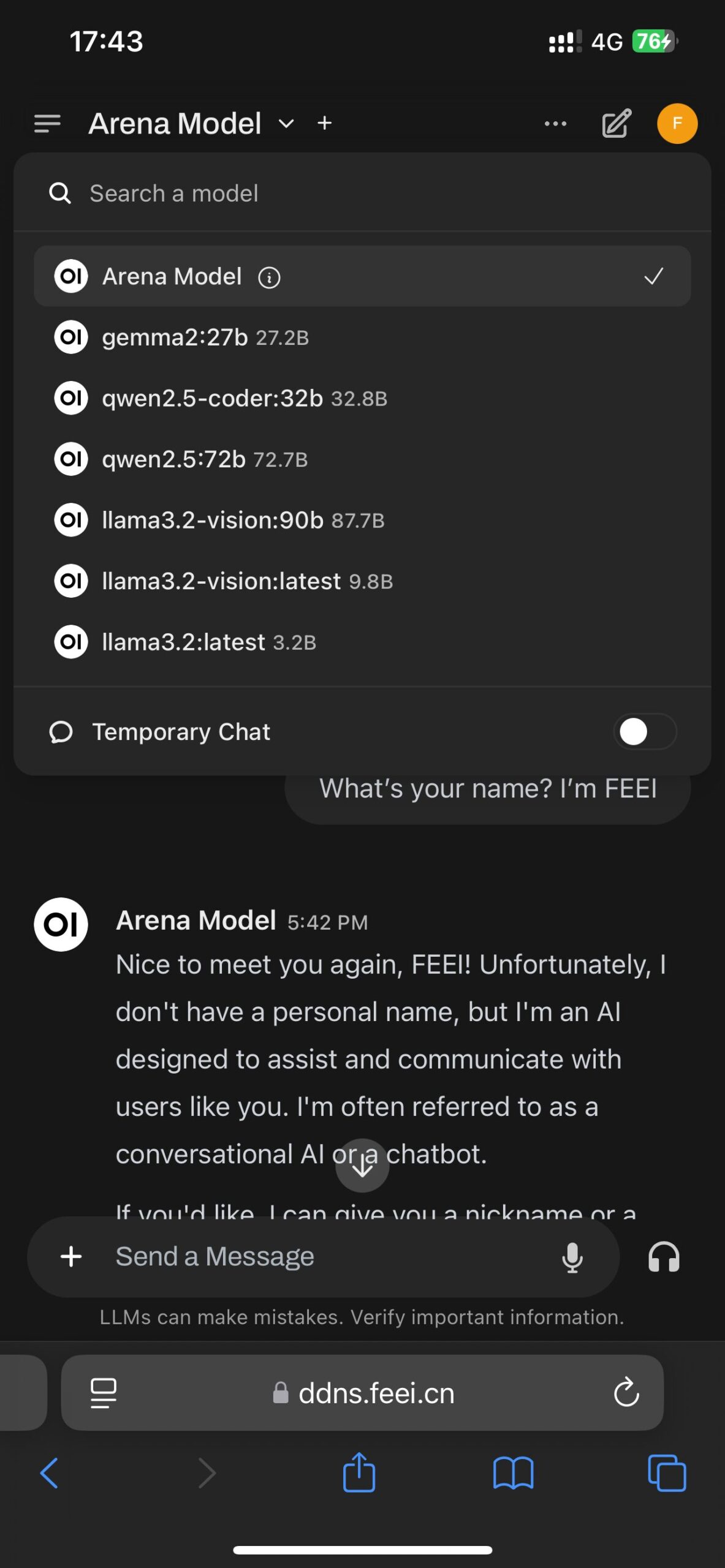
Using Local LLM Everywhere